
Kubernetes 是容器编排工具,负责在多台机器组成的集群上调度容器。用户只需要使用Kubernetes 资源来声明希望集群达到的状态,Kubernetes 就会调度集群资源,自动满足所声明的状态。
使用 Kubernetes,用户不用再操心容器具体的部署过程,而是使用声明式的方法来进行应用部署,大大简化了运维工作,使得程序员可以更专注于业务的的开发。
可以看出,使用 Kubernetes,我们更关心的是集群中的各种资源的管理,下面就是 Kubernetes 中常见的资源。
更值得注意的是,Kubernetes 是通过控制器(Controller)来调谐资源的,一个控制器只需要关注自己的资源,并通过创建下一个层级的资源,来让底层控制器进行协调即可。也正因如此,Kubernetes 中的资源是有层级关系的。
目录
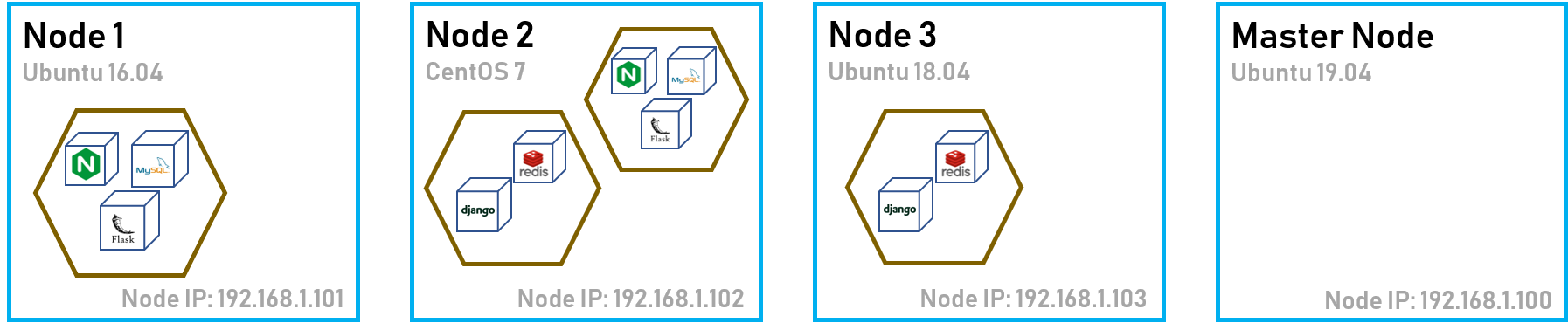
Node
任容器技术被怎么吹上天,还是要有一个 Host OS 来运行它们。而在 Kubernetes 中,一个独立的拥有 IP 的操作系统,并且运行着 Kubernetes 服务,就可以认为是一个 Node。

当然,既然是管理,那么就需要有节点站出来作为集群的管理者,这种节点被称为 Master Node,负责给手下的节点布置任务,来满足用户的需求。
Pod
在 Kubernetes 中,调度的最小单元并不是容器,而是一个 Pod。Pod 可以认为是一台小小的虚拟机,而里面作为进程运行着的就是真正的 Container。
因此,一个 Pod 资源只需要声明其中使用到的 Container 即可。而由于 Pod 是调度的最小单位,所以我们可以在 Pod Spec 中指定调度的规则,例如,Node 的亲和性,又或者是 Pod 之间的亲和性。比如你可能不想让运行数据库的 Node 再被调度其他的 Pod 以免影响性能,那么可以在 Pod 中指定规则。
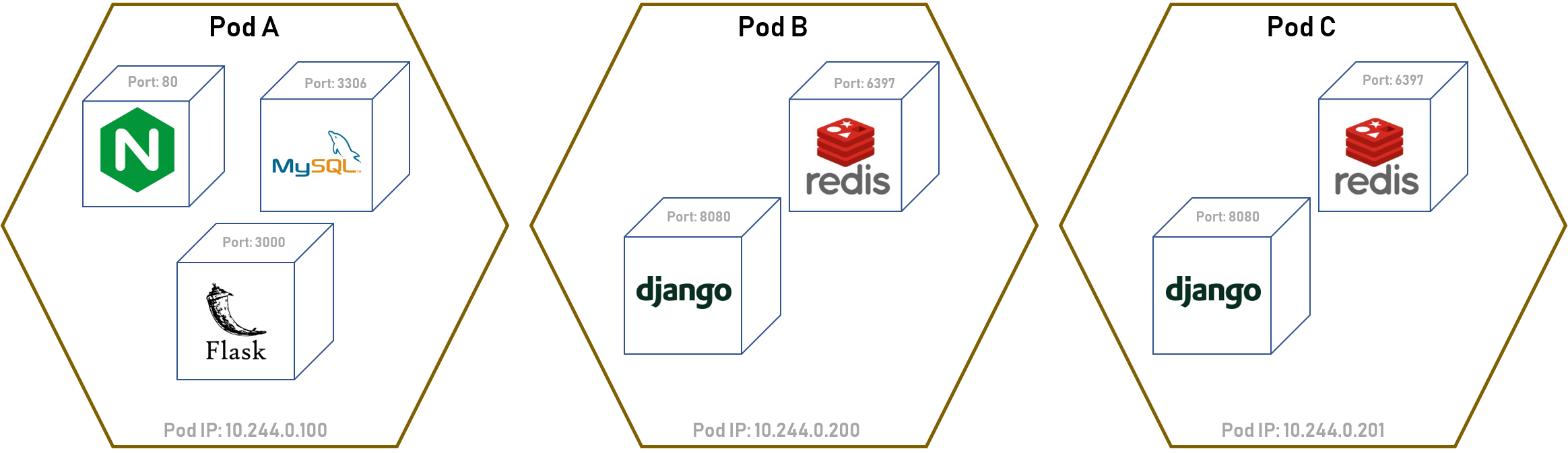
每个 Pod 都会拥有一个自己的虚拟 Pod IP,而 Pod 内的容器则共享这个 IP,因此 Pod 里的容器是不可以有端口冲突的,而 Pod 内的容器可以很方便地使用对方的端口和 localhost 地址进行通信。Pod 之间也可以通过 Pod IP 进行通信。
ReplicaSet
定义了 Pod 之后,Kubernetes 就已经可以开始调度容器了。但是,如果想要一次运行多个 Pod,手动创建多个 Pod 并不是一个好的选择,万一 Pod Spec 发生变化,就要一个个去改。因此,用户可以通过 ReplicaSet 来告诉 Kubernetes 自己的 Pod 需要执行多少个。顾名思义,ReplicaSet 是控制 Pod 运行数量的资源。

Deployment
由于单独定义 Pod 和 ReplicaSet 有时候过于麻烦,因此 Kubernetes 将这两种资源控制器合并在一起变成 Deployment。我们只需要在其中描述我们的 Pod,并且指定数量,Kubernetes 就会自动帮我们创建 Pod 和 ReplicaSet,帮助我们调度 Pod,使集群达到理想的状态。同时,如果我们想进行滚动升级,那么 Deployment 实际上会创建一个新的 ReplicaSet,并慢慢调大新 ReplicaSet 的数量,并减少旧的 ReplicaSet 的数量,从而达到逐步更新的效果。当然,要是发现升级过程出现什么问题,我们也可以快速回滚,也就是将新的 ReplicaSet 副本数量调低,旧的调回来。
Service
虽然我们可以使用 Pod IP 来进行应用之间的通信,但是在实际场景中,一个 Pod 很可能会因为 Node 上的资源不足或者因为出错而被杀掉并重新调度,导致自己的 Pod IP 改变。所以如果直接在应用中直接使用 Pod IP 来和其他服务通信的话,会带来许多麻烦。因此,Kubernetes 诞生了一个叫 Service 的资源。
Service 通过标签的方式,选择一组 Pod,并对外提供一个不变的名字,当集群内的应用需要访问 Pod 时,不再直接使用 Pod IP 访问,而是使用 Service 的名字进行访问。
当然,网络通信最终还是要 IP 地址的,因此在集群内部还有一个 DNS 负责解析 Serivce Name 到 IP 地址上。神奇的是,Service 解析到的 IP 并不是 Pod IP,而是这个 Service 对应的 Cluster IP。Kubernetes 会在 Node 上设置正确的 iptables/ipvs 规则,使得 Node 上的应用访问这个 Cluster IP 的流量会被随机的转发到一个 Pod 上。
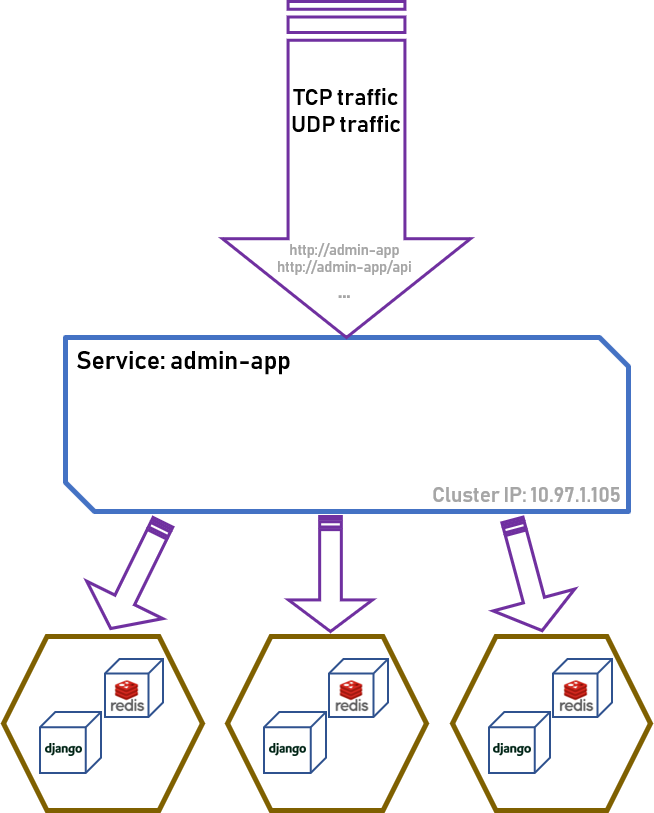
这样,通过 Service 我们就再也不怕 Pod 的增减和变动了,能通过不变的名字访问服务。
DaemonSet
由于 Deployment 并不能保证同一个 Pod 不会调度到同一个 Node 上,而有一些应用我们希望每个机器上都恰好运行一个,比如日志的收集、节点的监控。这时候可以借助 DaemonSet 来运行这类守护容器。
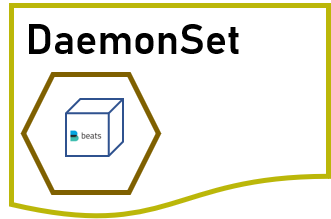
DaemonSet 和 ReplicaSet 类似,都是用来控制 Pod 的调度的,区别是 DaemonSet 不需要指定数量,Kubernetes 会安排每个 Node 恰好运行一个。
StatefulSet
有些像数据库一类的应用可能需要存储数据,甚至可能有主从的角色,主机必须要在从机之前启动,否则不能启动从机。为了部署这类有状态的应用,Kubernetes 提供了 StatefulSet 这一资源。
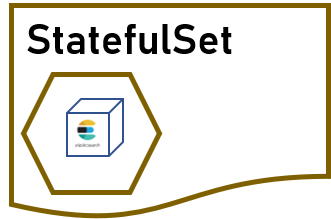
StatefulSet 相比 Deployment 有着更多的特性:
-
如果指定运行 n 个副本,那 Pod 会从 0 到 n – 1 依次创建,前面的创建不成功,后面就不会启动。
-
销毁的时候按照和创建相反的顺序删除 Pod,后面的 Pod 删除不成功,前面的就不会删除。
-
每个 Pod 都会有固定的标识来标识自己是第几个创建的 Pod,例如
elasticsearch-0。
PersistentVolume
前面提到 StatefulSet 需要存储数据,然而这些数据应该存储在哪里呢?肯定不能存储在 Pod 被调度到的机器上,这样万一 Pod 被调度到其他地方数据就不见了。为了解决这个问题,Kubernetes 提供了 PersistentVolume 来管理和 Pod 运行机器单独区分的存储资源,通常是存储服务器。

每个 PersistentVolume 都可以声明自己的容量、存储的引擎、被挂载的方式,声明了之后 Kubernetes 集群上的有状态应用就可以读写这些单独的存储资源,不需要怕被调度了。
但是 PersistentVolume 资源 Kubernetes 本身不能动态分配,需要系统管理员手动分配。
PersistentVolumeClaim
当然,由于是共享文件系统,肯定是不能随意读写的。一个应用不能直接挂载 PersistentVolume,而是要用 PersistentVolumeClaim 去声明自己需要使用 PersistentVolume,然后由 Kubernetes 集群分配合适的 PersistentVolume 供其读写。
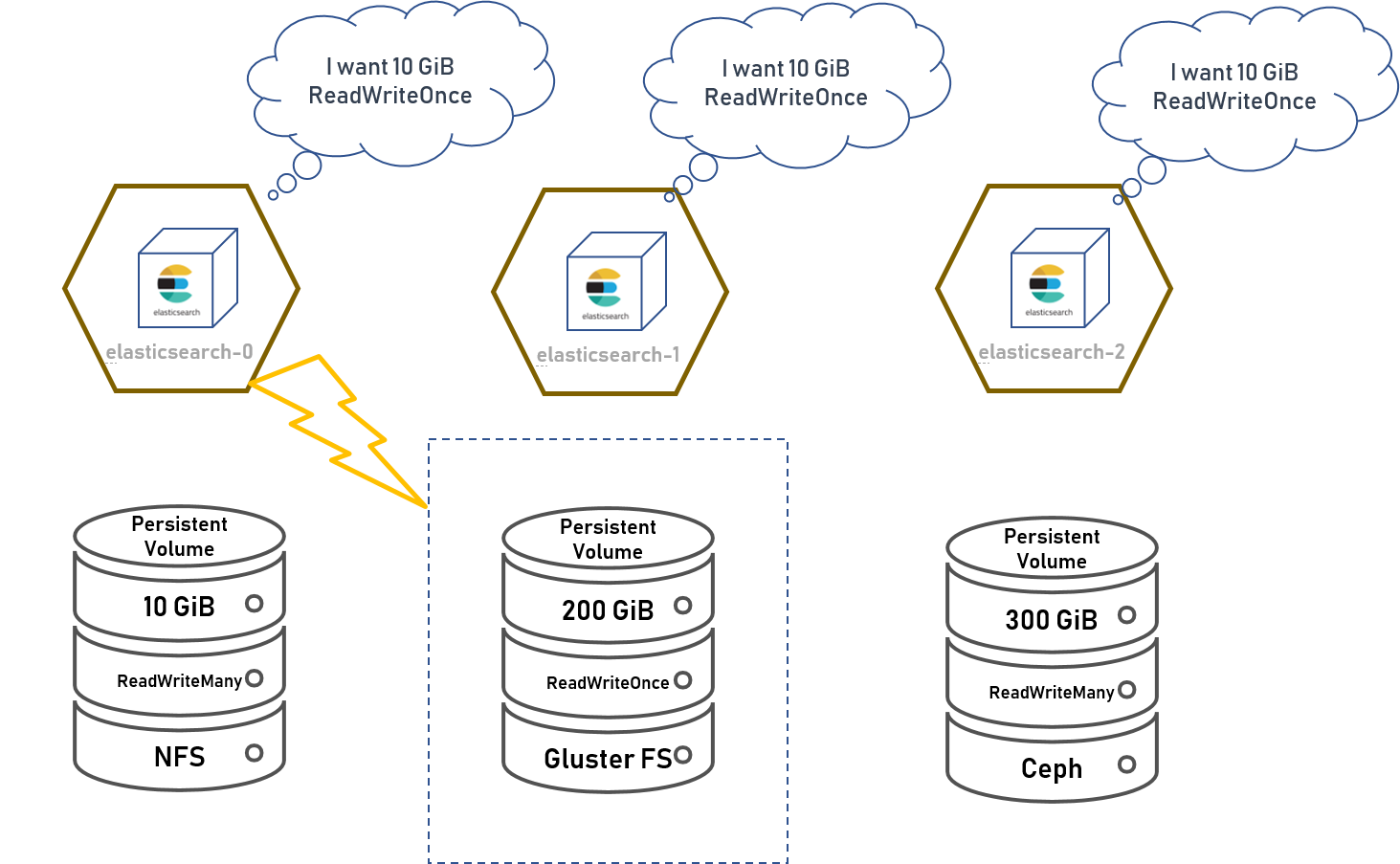
如果没有可以满足条件的 PersistentVolume,那 Pod 就不会被创建,直到有可用的 PersistentVolume 为止。