The Memory System: You Can’t Avoid It, You Can’t Ignore It, You Can’t Fake It 和 Innovations in Memory System 是 Synthesis Lectures on Computer Architecture 系列中关于内存的两本书。这篇文章总结了一些内存系统的细节。
内存条通常没有什么计算能力,只是作为内存控制器的一个从设备。内存控制器连接到主板上的内存通道(平时装机说的双通道就是内存通道),一个内存通道由地址/命令线和数据线组成。地址/命令线是单向的,从内存控制器到内存芯片,包含 a 位宽的地址线以及 c 位宽的命令线;数据线是双向的,包含 d 位宽的数据线。下面假设 a = 17, c = 5, d = 64。
内存通道通常运行在比 CPU 低的频率,我们买内存的时候标注的 DDR 是 Double Data Rate 的意思,也就是在时钟的上升和下降沿都传输一位数据,也就是说在一个时钟周期内,一条数据线可以传输 2d 位数据。需要注意的是,DDR 2400 的内存其实时钟频率是 1200MHz,而且地址/命令线运行的是单倍的数据传输率,也就是一个时钟周期只传输 a 位地址和 c 位命令。
为了支持这么高的通道频率,受物理电气的限制,内存通道的走线要比较短,而且负载不能太高。所以,一个内存通道上能连接的内存是有限的。高端服务器能插几十根内存条,也是因为主板上有很多的内存通道,而且不同的内存通道是由不同的内存控制器驱动的。
DDR 协议方便了内存厂商和 CPU 厂商,但是也成为了创新的一个阻力。DDR 的升级通常会带来更高的带宽以及更低的能耗,虽然 DDR5 已经面世,DDR6 还是有很大的不确定性。因为技术的升级往往会带来更高的错误率,所以新的 DDR 技术也会增加更多的保证可靠性的功能。
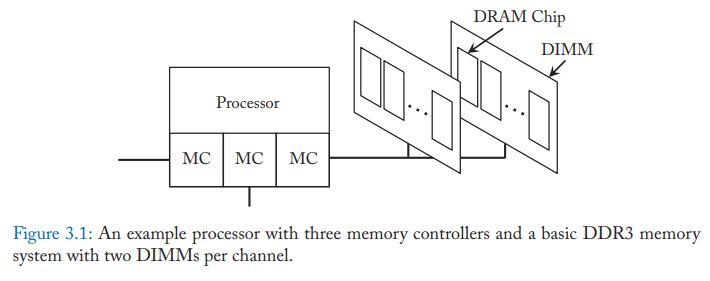

我们买的内存条叫 DIMM,电路板正面和背面都有 DRAM 芯片。主板上的插槽则对应内存通道,一个内存通道可能有多个插槽。DIMM 上有 Rank,一个 Rank 上的 DRAM 芯片是同时操作的,同时向数据总线读写数据。如果单个 DRAM 芯片的数据线是 8 位的,那么就叫做 x8 芯片,4 位的就叫 x4 芯片。假如数据总线是 64 位的,那么一个 Rank 需要 8 个 x8 芯片组合,或者 16 个 x4 芯片,这样才能满足数据总线的位宽。一个 DIMM 上可以有多个 Rank,例如正面是一个 Rank,背面是另一个。
一个内存通道里的一条数据线只会连接到一个 Rank 上的一个 DRAM 芯片引脚。如果内存通道支持 4 个 Rank,那么数据线就要驱动到 4 个不同引脚。为了避免总线过载,Rank 数量不能太大。一个内存通道里的地址/命令线则同时连接到了通道里所有 Rank 的每一个 DRAM 芯片上。因为负载太大,所以地址/命令线并没有采用 DDR,否则会导致信号不稳定。有时候为了进一步减少负载,DIMM 上面可能也有一个缓冲芯片,接收地址/命令后,再由缓冲芯片广播到每一个 DRAM 芯片上,这样每个地址/命令线都只需要驱动所有 DIMM 上一个单独的芯片就可以了。
因为 DRAM 芯片电路相对来说还是比较慢的,从一个 Rank 中读取数据可能需要花费 40 ns,如果我们每次都等上一个内存请求完成之后再进行下一个内存请求,那么内存系统将会慢的难以接受。和 CPU 类似,内存系统也有流水线。当内存请求在地址/控制线上发送之后,和这个请求相关的一个 Rank 内 DRAM 芯片就开始激活电路,读取数据,然后再将数据放到数据总线上发回。当一个 Rank 还在读取数据的时候,地址/控制总线就可以向其他 Rank 同时发起请求了。这样,不同 Rank 就可以同时并行地读取数据了。当然,最终数据的发回还是串行的,因为它们都连接到了一条共享的数据总线上。
这三个流水线阶段时间非常不平衡,例如发送地址/命令只需要 1 ns,读取数据则可能需要 35 ns,最终数据总线的传输需要 5 ns。虽然一个内存通道可以支持多个 Rank,但也并不会太多,例如常见的台式机上面只有双通道四插槽,那么其实每个通道只有 4 个 Rank。如果我们只利用 Rank 的并行,那么最多只能有 4 个并行的请求,还无法充分地利用流水线重叠请求。
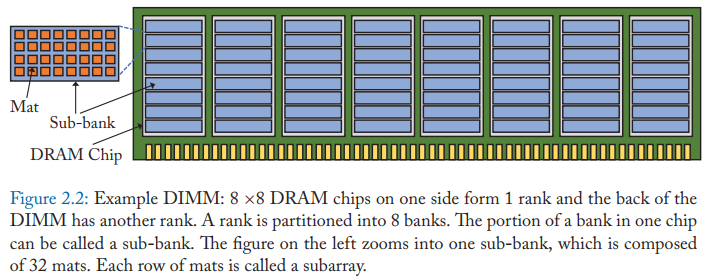
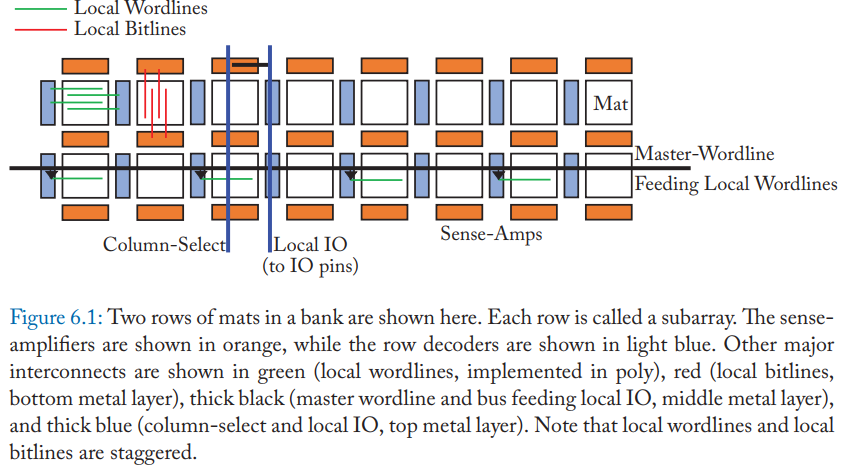
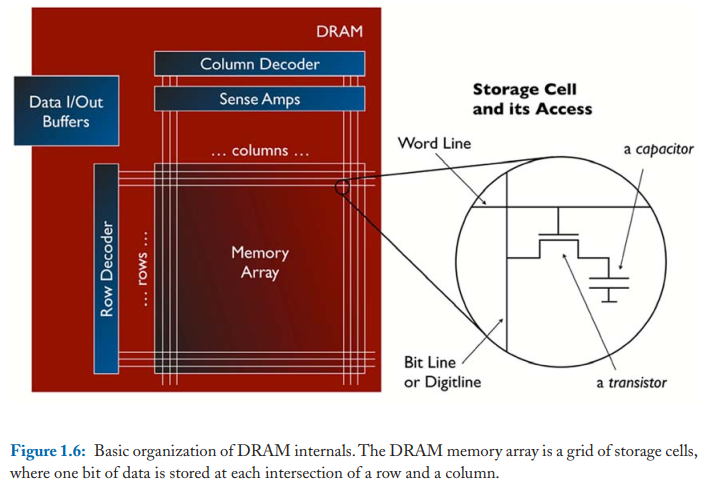
所以,每一个 Rank 内还会划分成多个 Bank。假如一个 Rank 内再划分了 8 个 Bank,那么一个内存通道就有 32 个 Bank。每个 Bank 可以独立地处理请求,大大地增加了并行度,提高了数据总线的利用率。如果一个 Rank 由 8 个 DRAM 芯片组成,那么这个 Rank 里的每一个 Bank 都会横跨这 8 个芯片。每个 Bank 内部还会划分成子 Bank,一个子 Bank 指的是那个 Bank 的在每一个内存芯片上的每一部分。每个子 Bank 包含子 Array 和比特矩阵,这样做是为了减少数据查找的延迟以及互联的开销。一个子 Array 就是子 Bank 里比特矩阵矩阵的一行。每个比特矩阵其实就是 DRAM 单元组成的一个矩阵,每个 DRAM 单元存储 1 位数据。如果这个比特矩阵有 512 行 x 512 列,那么这个矩阵就有 256 Kb 容量。横跨一行的线叫字线,而在每一行里,每个 DRAM 单元连接的纵向的线叫位线。在每个矩阵下面都有负责处理位线信号的放大器。读取一行数据到放大器需要大概 13 ns,这也叫行激活,由 RAS 命令发起。
CPU 以一个 Cache Line 为单位向内存发起读写请求。常见的 Cache Line 大小是 64 字节。这 64 字节会分散在组成这个 Rank 和 Bank 的所有 DRAM 芯片上。如果一个 Rank 由 8 个 x8 的芯片组成,那意味着每个芯片贡献了 Cache Line 的 64 位,这 64 位又分散在了子 Bank 里的多个矩阵里。所以,一次 Cache Line 读取请求,可能会涉及到 64 个不同矩阵一行 512 位宽的数据的读取。所以,所有放大器加起来会保存 32 Kb(4 KB)的数据,一个 Bank 里保存有效数据的放大器就叫行缓冲。请求的 64 字节的 Cache Line 则从这 4 KB 的数据里截取出来,通过数据总线传输回内存通道。这时,每个矩阵负责 8 位。这个过程由 CAS 命令发起。可以看出,一次 Cache Line 的传输,虽然只需要读取 64 字节数据,但实际上激活了 4 KB 数据,这种情况就叫 “overfetch”,如果下一次 Cache Line 请求已经在行缓冲区中,那么就不用重新读取矩阵了,行缓冲充当了 DRAM 里的 Cache!
当数据读取完成后,需要 8 次 64 位的传输,每次 64 位传输里,8 个芯片里的每个负责其中不同的 8 位。因为我们使用的是 DDR,所以 8 次传输只需要 4 个内存时钟周期。
需要注意的是,一个 Bank 里同时只有一行能够被激活,在行里的数据可以读取之前,需要给 DRAM 单元充电,这个过程大概需要 13 ns,一旦充电完成,之前存放在行缓冲中的数据就丢失了。
因此,实际上内存请求还可以进一步细化为三类。第一类就是命中行缓冲的,这时候访问延迟最低,只需要 13 ns,也就是将缓冲中的数据传输到 DRAM 芯片的输出引脚的延迟;第二类是空的行访问,也就是行缓冲中没有数据,并且位线已经预充电好了,这时候需要 13 ns 来将数据传输到行缓冲,再需要 13 ns 传输到 DRAM 芯片的输出端口;第三类情况是,行缓冲中已经有数据了,而且需要访问不同的行,这时候需要 13 ns 给位线充电,13 ns 将数据传输到行缓冲,再需要 13 ns 传输到输出端口。内存控制器需要负责在合适的时机发起预充电命令,以增加第一、二类请求的可能性。
当 LLC 未命中的时候,内存访问延迟可能超过 100 ns,比如说有 60 ns 的时间,请求在内存控制器中排队,39 ns 的时间花在第三类请求的处理上,然后有 4 ns 的时间用于数据总线的传输。
看到这里,相信你也有点晕了,我也有点晕了,作者也觉得这确实太绕了。总的来讲,内存系统也是有自己的层次化结构的,从大到小分别是 DIMM、Rank、Bank、子 Bank、子 Array、比特矩阵。对于装机人员,只关心 DIMM;对于设计内存系统的工程师,则主要研究 Rank 和 Bank 带来的并行度;而微架构工程师,也就是负责内存的电路设计的人员,就主要关心子 Bank、子 Array、比特矩阵的具体物理组织方式。

CPU 发起的内存请求会先放到请求队列中,然后内存控制器翻译 CPU 请求,发送到 DRAM 队列,每个 DRAM 队列对应的是单独的内存通道。每个队列对应的是单独的内存控制器。为了增加带宽聚合在一起的内存通道通常共享同一个控制器和队列。至于物理上的 DRAM 队列是怎么实现的,通常会按 Rank 划分队列和按 Bank 划分队列。按 Bank 划分有两种方式,一种是 Bank i 的请求全部发往同一个队列,不管 Rank 是多少。另一种是每个 Bank 都有自己的队列。按 Bank 划分可能是现代计算机中限制每个内存通道的 Rank 数量的瓶颈。DRAM 队列里存放的命令包含通道号、Rank 号、行号和列号。
CPU 的命令和 DRAM 的命令都可能被乱序调度执行(而不是 FIFO)。调度器应该尽可能地保持一行是打开状态的,这样可以处理行缓冲命中的情况,这称为 Open-page 策略,对于局部性好的程序很友好。但是这个策略会导致在发生行缓冲冲突的时候有很大的延迟,所以如果程序的局部性不好,那么采取 Close-page 策略会更好,也就是在一行读完之后,就马上给位线充电,清空行缓冲。现在的内存控制器使用的是介于这两者之间的调度算法。
此外,虽然数据总线是双向的,但是每次切换方向的时候也会有一定的延迟,称为总线转向时间,大约需要 7.5 ns。所以,读和写都是分别分批处理的。读比较重要,总是第一时间处理,写的话有 Write Buffer,等 Buffer 快满了之后才切换总线方向,然后一大批地写。
为了提高行缓冲的命中率,调度器需要在每一个时钟周期都检查队列中的请求,使用 FR-FCFS 算法,尽可能选择已经充电好的请求处理,但这会导致一些线程优先级过高,需要另外的算法保证公平性。
虽然读内存的时候,CPU 是以 64 字节为单位取到缓存里,但是内存在读取数据返回给总线的时候,是需要多个时钟周期的,这些时钟周期也叫节拍。如果数据总线是 64 位(8 字节)的,那么就需要 8 拍才能把数据传输完。
DRAM 返回数据的时候,并不是直接发送到 CPU,而是先到内存控制器的缓冲区,然后再传送到 CPU。这样做的好处就是可以允许两个带宽不一致,CPU 的带宽和 DRAM 的带宽可以不同。在一些乱序的总线上,可以通过事务 ID 来区分不同的请求。
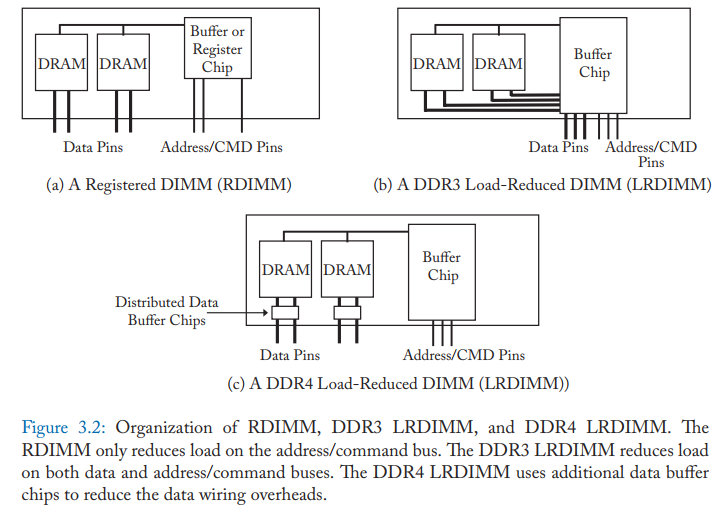
为了减轻内存控制器以及总线的电流负载,一些 DIMM 上可能会带有额外的缓冲区芯片,RDIMM 只在地址/命令线添加缓冲区,缓冲区将地址/命令数据广播到 DRAM 芯片上,DRAM 芯片的数据引脚仍然直接连接到数据总线。而 LRDIMM 则是将数据引脚也接入到缓冲区,DDR 3 是接入到一个大的缓冲区,DDR 4 则是每个DRAM 芯片有自己的缓冲区。
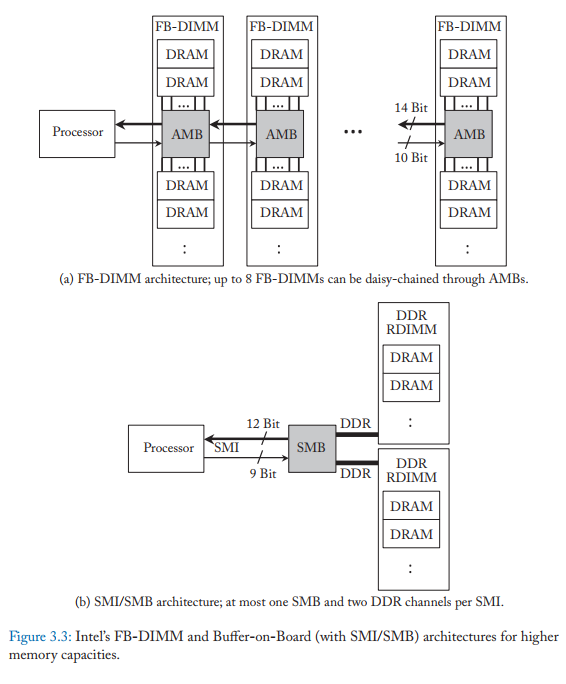
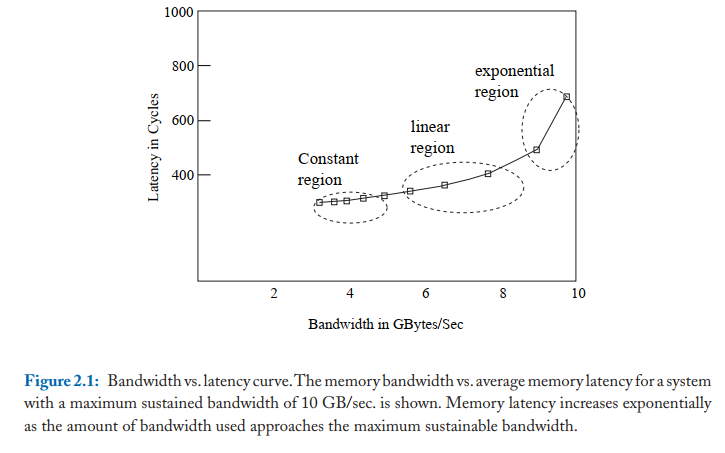
实际的带宽最大值往往只有理论最大值的 65%~75%,随着内存带宽使用率上升,内存延迟也会上升。带宽利用率不同阶段的延迟上升程度不一样。
另外,由于内存控制器队列、硬件 Prefetcher、总线利用率、DIMM Rank 和 Bank 都可能影响内存访问的延迟,在使用理论模型分析内存访问延迟的时候,不能简单地认为内存访问延迟是一个常数,而是需要更加复杂的访问模型来计算,例如下面的伪代码就考虑了总线带宽,硬件 Prefetch 的影响。对于复杂的系统,必须使用更复杂的模型,否则结果将出现相当大的偏差,造成“Garbage in, garbage out”的结果。

目前 DDR DRAM 的内存发展遇到了一定的瓶颈,HBM 等新技术也开始得到广泛应用。另外,为了解决 CPU 和内存之间的传输瓶颈,近数据处理也成为了热门话题,例如 In-Memory Computing。有的是利用了内存的物理电气规律来进行简单的逻辑运算,有的则是在内存芯片上安装额外的简单的处理器。目前这个领域也是方兴未艾,相关的编程语言等支持也还在研究之中。