练习 1 加载应用程序并执行
在 load_icode 中,前面的函数体负责初始化内存内容和拷贝相应的内容到内存中,最后需要一种方法,使得 CPU 可以从用户进程入口处开始运行。
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = USTACKTOP;
tf->tf_eip = elf->e_entry;
tf->tf_eflags = FL_IF;
ret = 0;在中断返回之后,CPU 会使用 trapframe 中的值设置寄存器,特权级的切换则发生在这里。所以,我们要设置 tf 中的段寄存器,使其进入用户空间。
同时,用户使用的栈和内核栈也不同,需要设置栈指针到用户栈的栈顶。
而返回后应该从 elf 文件的入口开始执行,所以设置 eip 的指针到 elf 的入口。
最后,需要重新打开 CPU 的中断开关,以便操作系统可以处理中断。
可以看到,在创建了 Lab 4 中的两个内核线程之后,紧接着 init_proc 会创建一个 user_main 的内核线程:
static int
init_main(void *arg) {
size_t nr_free_pages_store = nr_free_pages();
size_t kernel_allocated_store = kallocated();
int pid = kernel_thread(user_main, NULL, 0);
if (pid <= 0) {
panic("create user_main failed.\n");
}
while (do_wait(0, NULL) == 0) {
schedule();
}
cprintf("all user-mode processes have quit.\n");
assert(initproc->cptr == NULL && initproc->yptr == NULL && initproc->optr == NULL);
assert(nr_process == 2);
assert(list_next(&proc_list) == &(initproc->list_link));
assert(list_prev(&proc_list) == &(initproc->list_link));
cprintf("init check memory pass.\n");
return 0;
}在创建好供用户进程运行使用的内核线程会进入 do_wait 函数:
int
do_wait(int pid, int *code_store) {
struct mm_struct *mm = current->mm;
if (code_store != NULL) {
if (!user_mem_check(mm, (uintptr_t)code_store, sizeof(int), 1)) {
return -E_INVAL;
}
}
struct proc_struct *proc;
bool intr_flag, haskid;
repeat:
haskid = 0;
if (pid != 0) {
proc = find_proc(pid);
if (proc != NULL && proc->parent == current) {
haskid = 1;
if (proc->state == PROC_ZOMBIE) {
goto found;
}
}
}
else {
proc = current->cptr;
for (; proc != NULL; proc = proc->optr) {
haskid = 1;
if (proc->state == PROC_ZOMBIE) {
goto found;
}
}
}
if (haskid) {
current->state = PROC_SLEEPING;
current->wait_state = WT_CHILD;
schedule();
if (current->flags & PF_EXITING) {
do_exit(-E_KILLED);
}
goto repeat;
}
return -E_BAD_PROC;
found:
if (proc == idleproc || proc == initproc) {
panic("wait idleproc or initproc.\n");
}
if (code_store != NULL) {
*code_store = proc->exit_code;
}
local_intr_save(intr_flag);
{
unhash_proc(proc);
remove_links(proc);
}
local_intr_restore(intr_flag);
put_kstack(proc);
kfree(proc);
return 0;
}在 do_wait 函数中,会检查当前进程是否有孩子进程,如果找到了孩子进程,就检查看孩子进程是否为 PROC_ZOMBIE 状态,由于 user_main 刚刚创建,所以是 PROC_RUNNABLE 状态。当操作系统发现有孩子进程还没有执行完成的时候,就会将父进程置为 PROC_SLEEPING 状态,然后调用调度器。
而在调度器中,会选择下一个可以运行的进程,也就是 user_main 进程。此时调用 proc_run 切换到了 user_main 函数。
而在 user_main 中,会马上调用 kernel_execve 加载用户程序开始执行:
static int
user_main(void *arg) {
#ifdef TEST
KERNEL_EXECVE2(TEST, TESTSTART, TESTSIZE);
#else
KERNEL_EXECVE(exit);
#endif
panic("user_main execve failed.\n");
}而 kernel_execve 是一个系统调用,调用后会进入内核态执行 do_execve 做必要的准备工作:
static int
kernel_execve(const char *name, unsigned char *binary, size_t size) {
int ret, len = strlen(name);
asm volatile (
"int %1;"
: "=a" (ret)
: "i" (T_SYSCALL), "0" (SYS_exec), "d" (name), "c" (len), "b" (binary), "D" (size)
: "memory");
return ret;
}SYS_exec 就是调用 do_execv 函数了,用户进程代码在这个函数里使用 load_icode 被装载,并且设置好入口的地址。
等到 do_execv 执行完毕后,trapframe 内容的 eip 已经被设置为用户代码的入口地址,从中断 iret 返回后,eip 就会被设置为用户进程的第一条代码了。
编译用户进程代码的时候,可以看到连接脚本如下:
/* Simple linker script for ucore user-level programs.
See the GNU ld 'info' manual ("info ld") to learn the syntax. */
OUTPUT_FORMAT("elf32-i386", "elf32-i386", "elf32-i386")
OUTPUT_ARCH(i386)
ENTRY(_start)
SECTIONS {
/* Load programs at this address: "." means the current address */
. = 0x800020;
.text : {
*(.text .stub .text.* .gnu.linkonce.t.*)
}
PROVIDE(etext = .); /* Define the 'etext' symbol to this value */
.rodata : {
*(.rodata .rodata.* .gnu.linkonce.r.*)
}
/* Adjust the address for the data segment to the next page */
. = ALIGN(0x1000);
.data : {
*(.data)
}
PROVIDE(edata = .);
.bss : {
*(.bss)
}
PROVIDE(end = .);
/* Place debugging symbols so that they can be found by
* the kernel debugger.
* Specifically, the four words at 0x200000 mark the beginning of
* the stabs, the end of the stabs, the beginning of the stabs
* string table, and the end of the stabs string table, respectively.
*/
.stab_info 0x200000 : {
LONG(__STAB_BEGIN__);
LONG(__STAB_END__);
LONG(__STABSTR_BEGIN__);
LONG(__STABSTR_END__);
}
.stab : {
__STAB_BEGIN__ = DEFINED(__STAB_BEGIN__) ? __STAB_BEGIN__ : .;
*(.stab);
__STAB_END__ = DEFINED(__STAB_END__) ? __STAB_END__ : .;
BYTE(0) /* Force the linker to allocate space
for this section */
}
.stabstr : {
__STABSTR_BEGIN__ = DEFINED(__STABSTR_BEGIN__) ? __STABSTR_BEGIN__ : .;
*(.stabstr);
__STABSTR_END__ = DEFINED(__STABSTR_END__) ? __STABSTR_END__ : .;
BYTE(0) /* Force the linker to allocate space
for this section */
}
/DISCARD/ : {
*(.eh_frame .note.GNU-stack .comment)
}
}也就是说,用户进程都是加载到 0x800020 这个虚拟内存地址,而入口函数为 _start,这个是系统提供的函数,主要负责调用 umain 函数:
.text
.globl _start
_start:
# set ebp for backtrace
movl $0x0, %ebp
# move down the esp register
# since it may cause page fault in backtrace
subl $0x20, %esp
# call user-program function
call umain
1: jmp 1b而 umain 则负责调用用户提供的 main 函数:
#include <ulib.h>
int main(void);
void
umain(void) {
int ret = main();
exit(ret);
}到这里,进程进入用户的 main 函数,用户的代码便开始执行了。
练习 2 父进程复制自己的内存空间给子进程
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
assert(start % PGSIZE == 0 && end % PGSIZE == 0);
assert(USER_ACCESS(start, end));
// copy content by page unit.
do {
//call get_pte to find process A's pte according to the addr start
pte_t *ptep = get_pte(from, start, 0), *nptep;
if (ptep == NULL) {
start = ROUNDDOWN(start + PTSIZE, PTSIZE);
continue ;
}
//call get_pte to find process B's pte according to the addr start. If pte is NULL, just alloc a PT
if (*ptep & PTE_P) {
if ((nptep = get_pte(to, start, 1)) == NULL) {
return -E_NO_MEM;
}
uint32_t perm = (*ptep & PTE_USER);
//get page from ptep
struct Page *page = pte2page(*ptep);
// alloc a page for process B
struct Page *npage=alloc_page();
assert(page!=NULL);
assert(npage!=NULL);
int ret=0;
/* LAB5:EXERCISE2 YOUR CODE
* replicate content of page to npage, build the map of phy addr of nage with the linear addr start
*
* Some Useful MACROs and DEFINEs, you can use them in below implementation.
* MACROs or Functions:
* page2kva(struct Page *page): return the kernel vritual addr of memory which page managed (SEE pmm.h)
* page_insert: build the map of phy addr of an Page with the linear addr la
* memcpy: typical memory copy function
*
* (1) find src_kvaddr: the kernel virtual address of page
* (2) find dst_kvaddr: the kernel virtual address of npage
* (3) memory copy from src_kvaddr to dst_kvaddr, size is PGSIZE
* (4) build the map of phy addr of nage with the linear addr start
*/
void *src_kvaddr = page2kva(page);
void *dst_kvaddr = page2kva(npage);
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
ret = page_insert(to, npage, start, perm);
assert(ret == 0);
}
start += PGSIZE;
} while (start != 0 && start < end);
return 0;
}在 copy_range 中,最终完成了父进程的内存空间拷贝到子进程中的工作,实现思路比较简单。参数的 to 是子进程的页目录表,from 则是父进程的页目录表,start 是空间开始的虚拟地址,end 是空间结束的虚拟地址。在这个函数中,主要就是遍历每一个父进程中的页表项,然后为子进程分配新页,使用 memcpy 函数复制内存,最后插入到子进程的页表中。
如果要实现 Copy On Write 机制,则直接省去拷贝的操作,直接将父进程的页表项插入到子进程中。但是需要将 PTE_W 清零。这样,在两个进程访问到共享页面的时候,则会触发 Page Fault,而处理页面异常的例程发现虽然页表项不可写,但是所在的虚拟内存空间可写的话,就知道这是一次 Copy On Write 操作,到时候再进行复制即可。
练习 3 阅读分析源代码,理解进程执行 fork/exec/wait/exit 的实现,以及系统调用的实现
fork 的实现
fork 调用后最终会调用 do_fork 系统调用,子进程在其中被 wakeup_proc 函数唤醒,成为 PROC_RUNNABLE 态。
exec 的实现
exec 调用后最终会调用 do_execve 系统调用,此时进程被加载的用户程序完全替换,并且中断返回地址被设置成了用户程序的入口地址,但不会影响进程状态。
wait 的实现
wait 调用后最终会调用 do_wait 系统调用,在 do_wait 函数中,如果调用的时候指定的 pid 不为 0,则等待指定的子进程,如果调用的时候指定的 pid 是 0,则等待所有的子进程。
pid 不为 0 的时候,系统会检查当前进程是不是需要等待的父进程,然后检查子进程是否已经执行完毕成为 PROC_ZOMBIE 状态,如果是则对其进行清理,否则等待这个子进程执行完毕。
pid 为 0 的时候,系统会遍历当前进程所有的子进程,如果有任何一个执行完变为 PROC_ZOMBIE 状态,就清理掉。
在发现还没有执行完的子进程的时候,这个函数会把当前运行的进程设置为 PROC_SLEEPING 状态,并且等待状态设置为 WT_CHILD,并调用 schedule 函数,调度使子进程继续执行。
这个函数每次只会清理一个子进程,如果发现没有子进程了就会返回 E_BAD_PROC。所以需要在 while 循环中反复调用这个函数。
exit 的实现
exit 调用后最终会调用 do_exit 系统调用,在 do_exit 函数中,首先会清理进程所占用的内存,然后将当前进程设置为 PROC_ZOMBIE 态,然后查看当前进程的父进程是不是在 WT_CHILD 状态,是的话就唤醒这个父进程来清除自己。
对于这个进程而言,有可能有子进程还没有被清理,此时这些子进程都会被 init_proc 接管,并由 init_proc 负责清理。
ucore 中进程状态切换示意图如下:
alloc_proc RUNNING
+ +--<----<--+
+ + proc_run +
V +-->---->--+
PROC_UNINIT - proc_init/wakeup_proc --> PROC_RUNNABLE - try_free_pages/do_wait/do_sleep --> PROC_SLEEPING -
^ + +
| +--- do_exit --> PROC_ZOMBIE +
+ +
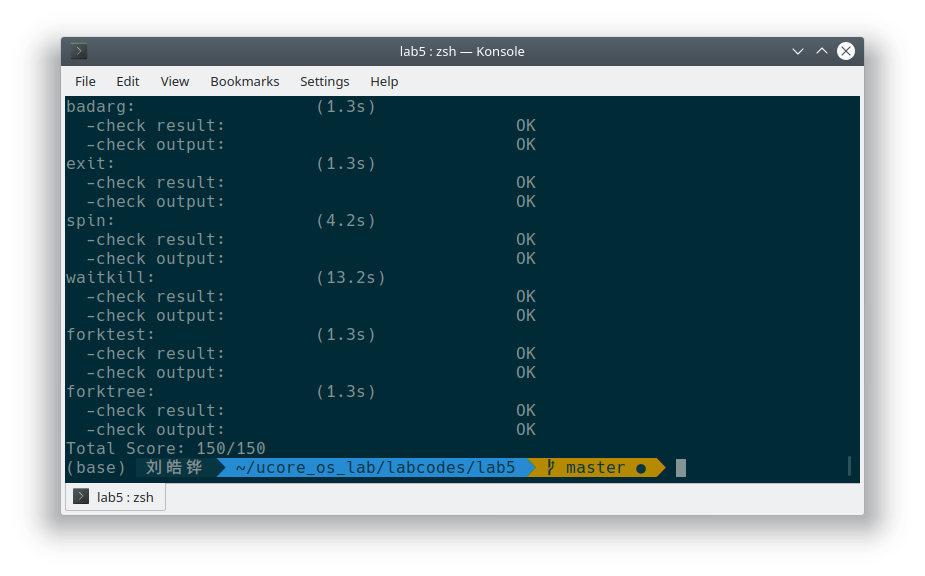
-----------------------wakeup_proc------------------------------实验结果
扩展练习 Challenge 实现 Copy On Write 机制
在 copy_range 中,判断父子进程是否共享内存:
if (share) {
if(*ptep & PTE_W){
perm &= (~PTE_W);
page_insert(from, page, start, perm);
}
ret = page_insert(to, page, start, perm);
} else {
void *src_kvaddr = page2kva(page);
void *dst_kvaddr = page2kva(npage);
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
ret = page_insert(to, npage, start, perm);
}在 COW 复制中,我们简单地插入同一个页表项即可,而且需要将可写标志位去掉。
然后,在 do_pgfault 函数中,添加对 COW 的处理:
struct Page *page=NULL, *npage=NULL;
bool COW = vma->vm_flags & VM_WRITE;
if (COW) {
npage = alloc_page();
if (!npage) goto failed;
}
if (*ptep & PTE_P) {
// COW
page = pte2page(*ptep);
} else {
// 需要换入页面
}
if (COW) {
if (page_ref(page) > 1) {
// Copy
memcpy(page2kva(npage), page2kva(page), PGSIZE);
// page_ref_dec(page);
page = npage, npage = NULL;
}
page_insert(mm->pgdir, page, addr, perm);
swap_map_swappable(mm, addr, page, 1);
if (npage) {
// 说明只有一个进程在共享这个页面,不需要复制了
free_page(npage);
}
}将 dup_mmap 中的 share = 0 改为 share = 1:
int
dup_mmap(struct mm_struct *to, struct mm_struct *from) {
assert(to != NULL && from != NULL);
list_entry_t *list = &(from->mmap_list), *le = list;
while ((le = list_prev(le)) != list) {
struct vma_struct *vma, *nvma;
vma = le2vma(le, list_link);
nvma = vma_create(vma->vm_start, vma->vm_end, vma->vm_flags);
if (nvma == NULL) {
return -E_NO_MEM;
}
insert_vma_struct(to, nvma);
bool share = 1;
if (copy_range(to->pgdir, from->pgdir, vma->vm_start, vma->vm_end, share) != 0) {
return -E_NO_MEM;
}
}
return 0;
}最终执行一下 make run-forktest 和 make run-forktree 查看 fork 功能是否正常:
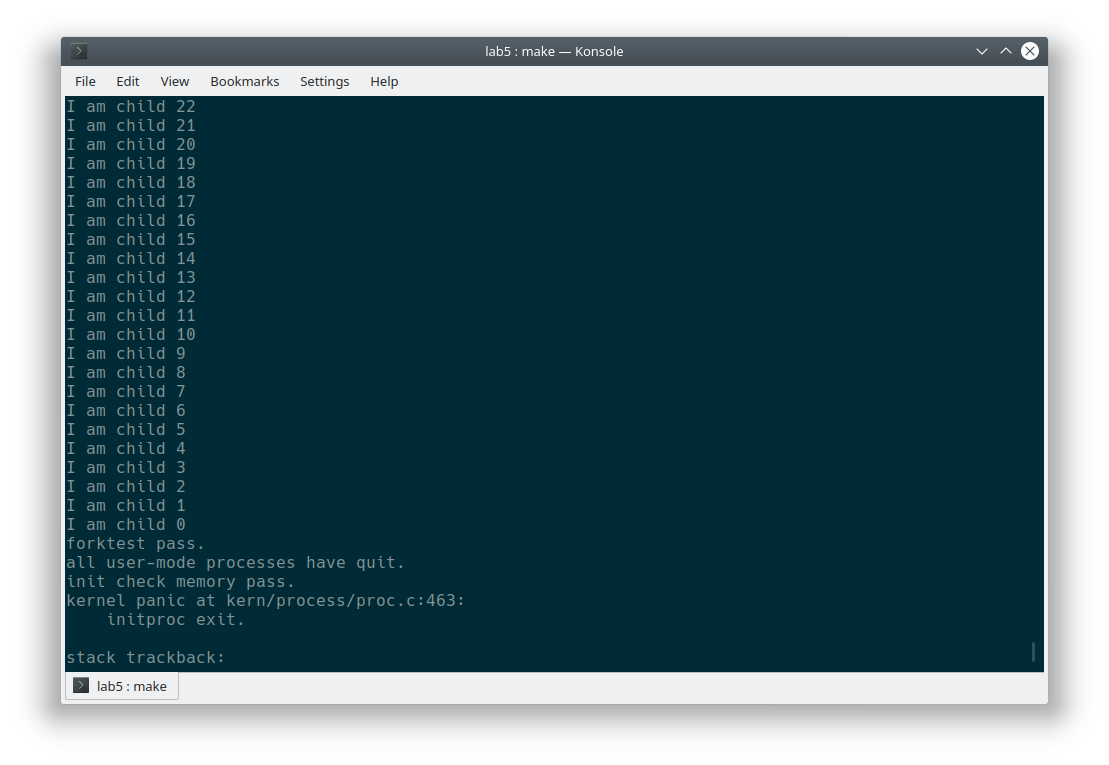
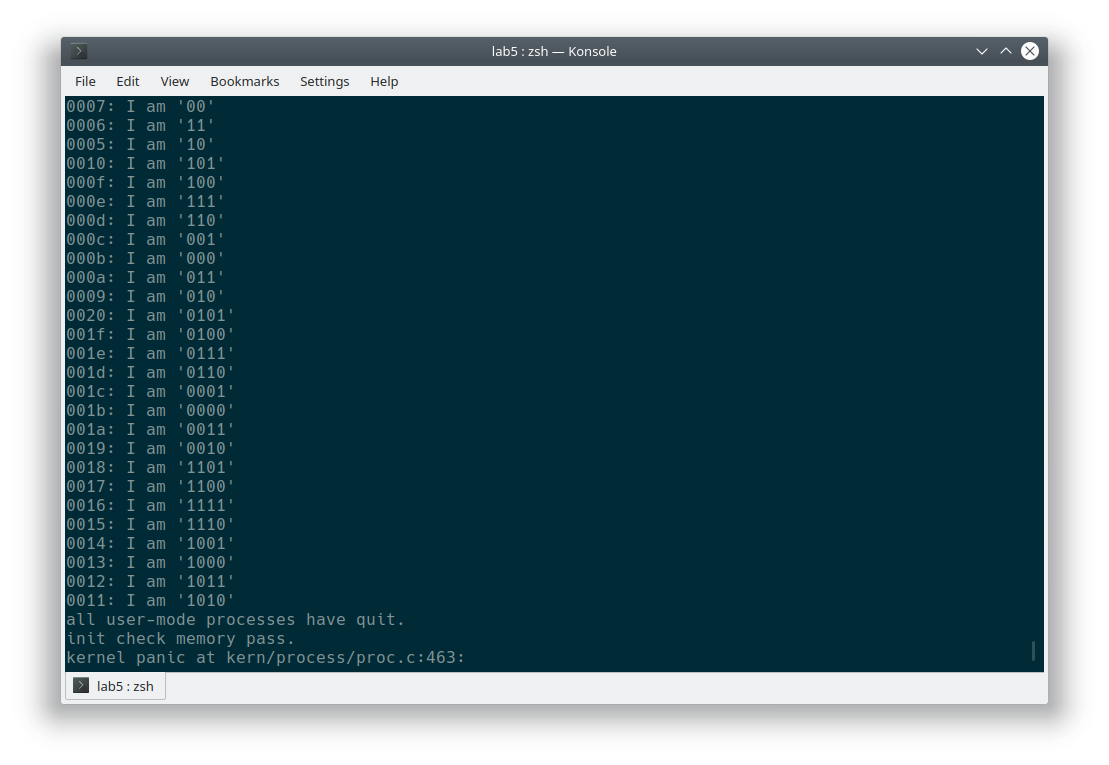
可以看到功能正常。