练习 1 实现 First-Fit 连续物理内存分配算法
First-Fit 连续物理内存分配算法实现比较简单。操作系统维护一个空闲页的链表,链表项根据对应地址从小到大进行排序。链表中的每一项包含的信息是连续空闲空间的第一页,同时 struct Page 中的 property 在 First-Fit 算法中意味着该连续空闲空间共有多少页。而在 flags 中,property 被置位的话,意味着这一页是连续空闲空间的第一页,Reserved 表示该页被操作系统保留,不能进行分配或者释放。在内存探测完成之后,所有的页都被保留了,需要在初始化函数中将其清零,否则不能被其他程序使用。
struct Page {
int ref; // page frame's reference counter
uint32_t flags; // array of flags that describe the status of the page frame
unsigned int property; // the num of free block, used in first fit pm manager
list_entry_t page_link; // free list link
};为了便于管理内存,定义 free_area_t 结构如下:
typedef struct {
list_entry_t free_list; // the list header
unsigned int nr_free; // # of free pages in this free list
} free_area_t;其中 free_list 是空闲链表的头,用来遍历空闲链表,本身不是一个页,nr_free 表示了总共有多少页是空闲的。
了解了各个字段表明的含义之后,就可以编写函数实现 First-Fit 物理内存分配算法了。
static void
default_init(void) {
list_init(&free_list);
nr_free = 0;
}首相是 default_init 函数,free_list 是空闲页链表的头,调用 list_init 对其进行初始化,并将 nr_free 置为 0 ,表示还没有空闲页纳入管理。
static void
default_init_memmap(struct Page *base, size_t n) {
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p ++) {
assert(PageReserved(p));
p->flags = p->property = 0;
set_page_ref(p, 0);
}
base->property = n;
SetPageProperty(base);
nr_free += n;
list_add_before(&free_list, &(base->page_link));
}default_init_memmap 函数的作用是,将以 base 开始连续的 n 个页加入到空闲链表中。首先需要确保每一页都是被内核保留的,然后将每一页的 flags 清零,表示该页可以被程序使用且不是连续空闲物理内存的第一页。最后将引用计数置为 0,表示还没有程序引用。然后将 base 的 property 设置为 n 并置 flags 中的 property 位,表示该页是连续空闲物理内存中的第一页。
最后,将 nr_free 加 n ,表示新增 n 页空闲页可用。由于函数是按照地址从小到大调用的,所以需要将基址加入到空闲链表的最后一项中。至此就完成了 default_init_memmap 的初始化工作。
static struct Page *
default_alloc_pages(size_t n) {
assert(n > 0);
if (n > nr_free) {
return NULL;
}
struct Page *page = NULL;
list_entry_t *le = &free_list;
while ((le = list_next(le)) != &free_list) {
struct Page *p = le2page(le, page_link);
if (p->property >= n) {
page = p;
break;
}
}
if (page != NULL) {
if (page->property > n) {
struct Page *p = page + n;
p->property = page->property - n;
SetPageProperty(p);
list_add_after(&(page->page_link), &(p->page_link));
}
nr_free -= n;
ClearPageProperty(page);
list_del(&(page->page_link));
}
return page;
}在分配页面时,需要首先检查剩余的空闲页是否够用,如果不够则分配失败,返回空指针。
然后,根据 First-Fit 算法,从地址小到大遍历每一个空闲块,一旦找到了足够大的空闲块就马上分配,也就是分配第一个足够大的空闲块给程序使用。找不到,说明没有这么大的连续空闲块,则返回空指针。
如果找到了这样的空闲块,还要检查空闲块的大小是否比需要分配的大小更大,如果是,则需要进行分裂。分裂的操作便是将空闲块的后面的空闲块重新形成空闲块,这个空闲块的第一个页面是 page + n,大小是 page->property - n,设置好 property 和 flags 中的 property 位后,在链表中加入到当前空闲块的后面(因为地址更大)。
最后将当前空闲块从空闲链表中删除,property 位清零,表明该页不是空闲块的第一页,并空闲块计数器减去 n,即完成分配,返回页表项指针。
static void
default_free_pages(struct Page *base, size_t n) {
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p ++) {
assert(!PageReserved(p) && !PageProperty(p));
p->flags = 0;
set_page_ref(p, 0);
}
base->property = n;
SetPageProperty(base);
list_entry_t *le = list_next(&free_list);
while (le != &free_list) {
p = le2page(le, page_link); // 检查链表中的每一个空闲块 p
le = list_next(le);
if (base + base->property == p) { // 被释放的空闲块后面紧接着空闲块 p
base->property += p->property; // 合并后面的空闲块 p
ClearPageProperty(p);
list_del(&(p->page_link)); // 释放掉后面的空闲块 p(因为已经合并)
}
else if (p + p->property == base) { // 被释放的空闲块前面紧接着空闲块 p
p->property += base->property; // 合并前面的空闲块 p
ClearPageProperty(base);
base = p; // 前面的空闲块 p 成为第一页
list_del(&(p->page_link)); // 释放掉自己
}
}
nr_free += n;
le = list_next(&free_list);
while (le != &free_list) {
p = le2page(le, page_link);
if (base + base->property <= p) {
assert(base + base->property != p);
break;
}
le = list_next(le);
}
list_add_before(le, &(base->page_link));
}最后 default_free_pages 负责已分配内存的释放。
首先确认每一个页面不是操作系统保留的而且不是空闲块第一页,然后清空属性。如果中途碰到了 property 置位的情况,说明释放的页面太多了,已经越界到下一个空闲块了。然后对于 base 页,重新设置对应的属性,表明其为大小为 n 页的空闲块的第一页,然后开始空闲块的合并。
对于被释放出来的空闲块,有三种可能:
- 这个空闲块后面紧接着链表中的某个空闲块。
- 这个空闲块前面紧接着链表中的某个空闲块。
- 情况 1 和 2 都发生了。
链表的合并过程需要遍历当前空闲链表中的每一个空闲块,然后检查这个空闲块是不是紧邻着新释放的空闲块,如果是,就合并它们。对于情况 3,程序会先将前面的空闲块合并成新的块,然后再合并后面的空闲块。
合并完成之后,由于需要维持链表有序,需要找到这个新的空闲块在链表中的插入位置。这里采用了插入排序的思想,遍历链表,找到第一个地址比需要插入的空闲块结尾地址大的空闲块,插入到它的前面即可。由于前面的过程保证了不会有空闲块越界和粘连的情况发生,所以判断条件改为 base <= p 也是可以的。
至此,First-Fit 连续物理内存分配算法就实现完成了。
•你的 First-Fit 算法是否有进一步的改进空间?
如果请求的内存大小不足一页,会造成空间上的浪费,这一点可以通过记录偏移和最后一次页面来改进。而且每一次操作都要进行链表的扫描,可以考虑使用哈希表来直接定位链表中的项。
练习 2 实现寻找虚拟地址对应的页表项
在 ucore os 中,一个一级页表(页目录)中的每一项指向二级页表(页表)的起始地址,每一个二级页表的大小为一页。因为一页大小为 $4096$ 字节,一个页表项(PTE)或者页目录项(PDE)占用 $4$ 个字节,因此每级页表都有 $1024$ 项可用,两级页表总共有 $1024 \times 1024 = 2^{20}$ 个页可用。需要注意的是页表中存放的都是物理地址。
pte_t *
get_pte(pde_t *pgdir, uintptr_t la, bool create) {
pde_t *pdep = pgdir + PDX(la);
if (!(*pdep & PTE_P)) {
struct Page* page;
if (!create || (page = alloc_page()) == NULL) {
return NULL;
}
set_page_ref(page, 1);
uintptr_t pa = page2pa(page);
memset(KADDR(pa), 0, PGSIZE);
*pdep = pa | PTE_P | PTE_U | PTE_W;
}
return (pte_t *)KADDR(PDE_ADDR(*pdep)) + PTX(la);
}要想获得 PTE,需要通过以下步骤实现:
- 通过
pgdir加上线性地址中的页目录偏移,得到指向页目录表项的指针pdep。 - 检查
pdep指向的表项是否有效(即指向一个有效的二级页表起始地址) - 如果无效,则分配一个新的页作为新的二级页表,然后得到这个页的物理地址并转换为内核虚拟地址,调用
memset将页清零。 - 将获得的地址填入到 PDE 中,并且设置为可读可写,该项有效。
- 最后获得 PDE 中的物理地址,转换为内核虚拟地址,得到二级页表的起始地址,加上 PTE 对应的偏移,就得到了真正的 PTE 地址。
-
请描述页目录项(Page Directory Entry)和页表项(Page Table Entry)中每个组成部分的含义以及对 ucore 而言的潜在用处。
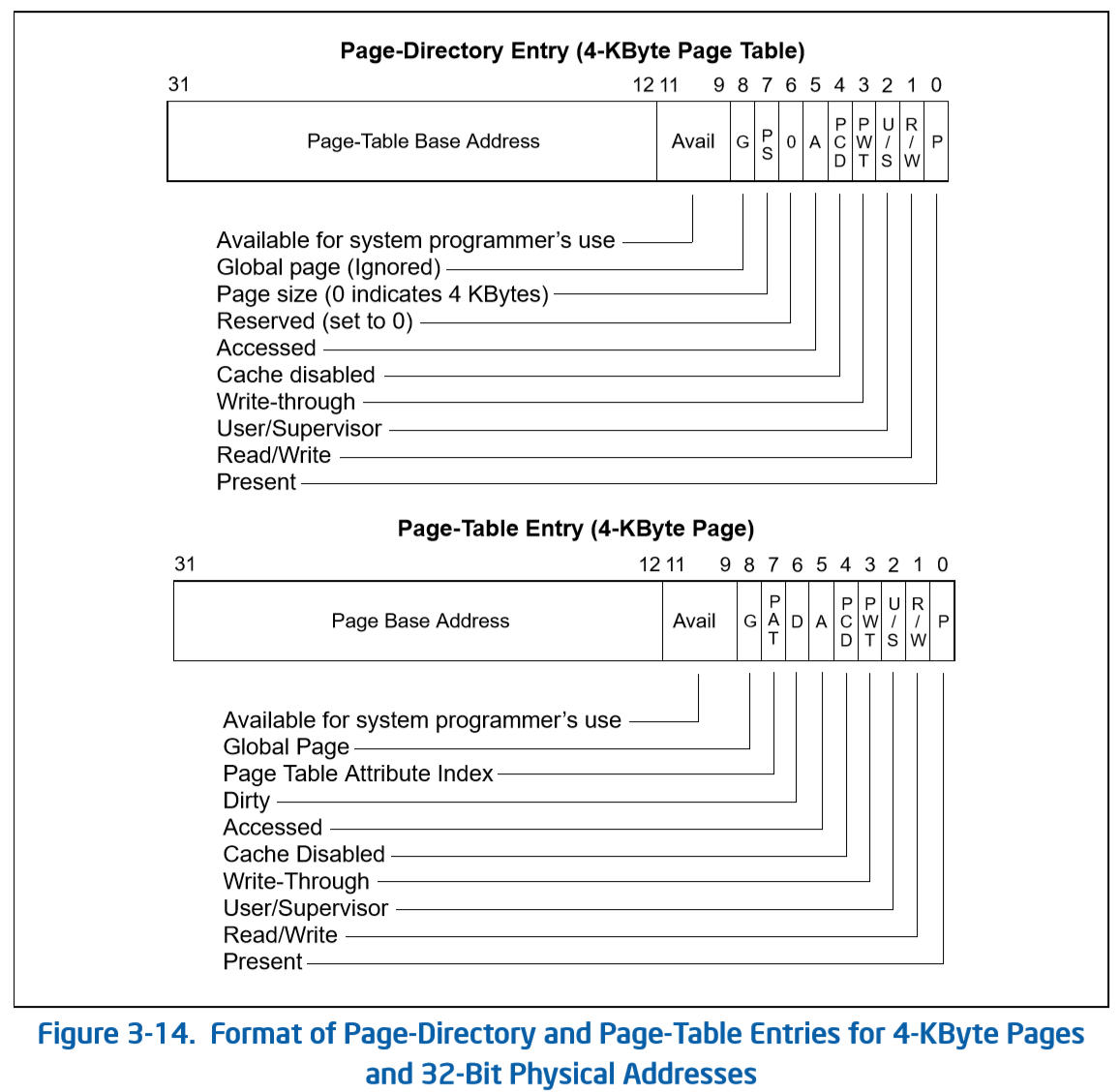
参考 Intel 官方手册,可以知道在页大小为 4KB 每页的时候,PDE 和 PTE 的高 20 位是物理基址,9-11 位为空闲位,操作系统可以自由使用。低八位为标志位,此时 PDE 与 PTE 的标志位含义有所不同,但它们的低三位都是一样的,分别用于权限控制,读写控制,以及标志该项是否有效。
-
如果 ucore 执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
-
将错误码压入栈中,表明此次页访问异常的具体错误,错误码具体格式如下:

-
将访问异常的线性地址放到
CR2寄存器中。 -
触发 14 号中断,将控制权移交中断服务例程。
-
练习 3 释放某虚地址所在的页并取消对应二级页表项的映射
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
if (*ptep & PTE_P) {
struct Page *page = pte2page(*ptep);
if (page_ref_dec(page) == 0) {
free_page(page);
}
*ptep = 0;
tlb_invalidate(pgdir, la);
}
}- 检查页表项是否有效,无效则不用处理。
- 获得页表项对应的页表信息,将其引用计数减一。如果页面不再被引用,则释放这一页。
- 将 PTE 置零,然后将对应的 TLB 缓存清除。
-
数据结构
struct Page的全局变量pages(其实是一个数组)的每一项与页表中的页目录项和页表项有无对应关系?如果有,其对应关系是啥?有。页目录项和页表项索引组合起来就是 PFN,也就是
pages数组的索引。 -
如果希望虚拟地址与物理地址相等,则需要如何修改 lab2,完成此事?
将开启分页这步操作先从
kern/init/entry.S取消,否则在分页模式,取消掉boot_pgdir[0]的页表下kern_init会被置于一个根本无法访问到的地址。然后:
- KERNBASE 调整回 0x00000000 。
- 链接脚本修改虚拟地址为 0x00100000 。
于是这样内核就会被置于正确的位置, eip 不会跑偏。
接下来的问题是
check_pgdir和check_boot_pgdir这两个检查函数会变得乱七八糟。它们都假设 KERNBASE 不为 0 ,所以会对 Linear Address 为 0 的地址为所欲为所欲为,比如查询 0 地址的页表分配、给 0 地址申请页表,对其动手动脚,写入数据等。不仅仅是威胁到内核安全,主要是页表操作失败本身就会导致断言失败。
验证测试
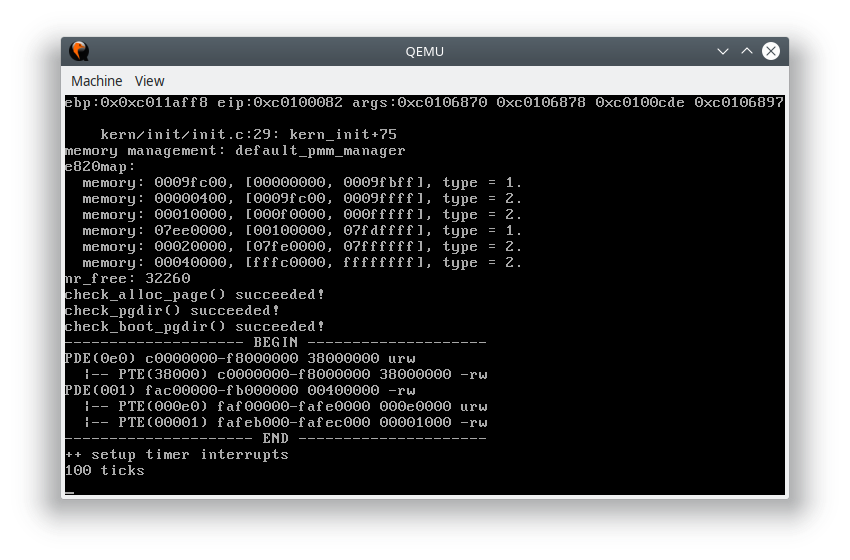
执行 make qemu 之后可以看到物理内存分配器成功地初始化,并且页表也成功建立完成。
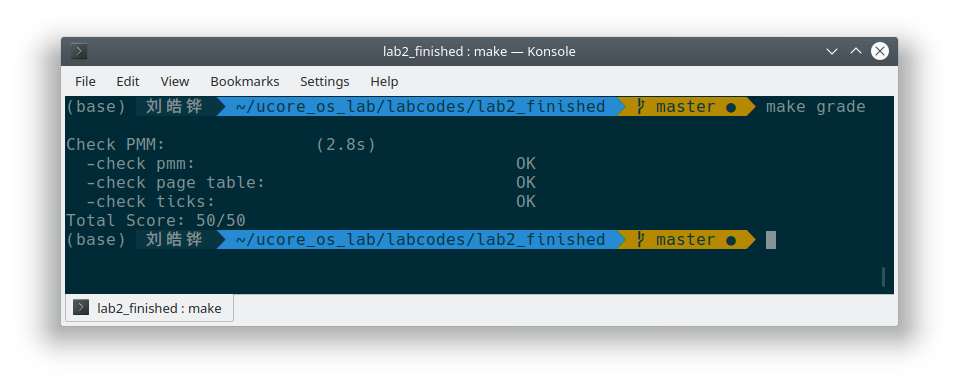
执行 make grade 之后可以看到打分成功了。
扩展练习 伙伴系统的实现
注:本实现参考了 Linux Kernel 2.6.0 中的内存管理,由其简化而来。Linux Kernel 2.6.24 之后的伙伴系统实现为了避免碎片化增加了额外的处理。由于只是想实现一个简单的伙伴系统,所以参考了比较简单的版本。
Linux Kernel 2.6.0 版本实现的伙伴系统采用了通过多个空闲链表来管理不同大小的空闲块的方式,一个空闲链表的阶 order 指的是空闲块大小的次数。一个阶为 order 的空闲链表中的每一个空闲块大小都是 2 ^ order 页。并且,总共管理的阶数数量定义为 MAX_ORDER == 11 ,也就是有 11 个空闲链表,最大的阶是 10。
在 Linux Kernel 2.6.0 中,伙伴系统的实现采用了每个空闲链表维护自己的 bitmap 的方法来标记该链表中一对伙伴的情况,一对伙伴只需要 1 位进行标记,如果该位为 0 则说明两个伙伴都没有使用或者都在使用,如果该位为 1 则说明两个伙伴只有其中之一被使用。在进行释放的时候,一个页面会有两种情况:
- 释放前伙伴位为 0,因为自己是要被释放的页面,所以可以知道释放后另一个伙伴还在使用,不能合并。
- 释放前伙伴位为 1,因为自己是要被释放的页面,所以可以知道释放后另一个伙伴也是空闲的,可以和自己合并成更大的伙伴块。
无论释放前情况如何,释放后都一定会改变伙伴位的值。
首先来看伙伴系统实现所需要的数据结构和一些辅助函数:
#define MAX_ORDER 11
#define MARK_USED(index, order, area) \
change_bit((index) >> (1 + (order)), (area)->map)
#define LONG_ALIGN(x) (((x) + (sizeof(long)) - 1) & ~((sizeof(long)) - 1))
typedef struct {
list_entry_t free_list;
unsigned long *map;
} buddy_free_area_t;
typedef struct {
buddy_free_area_t free_area[MAX_ORDER];
unsigned int nr_free; // how many free pages
} buddy_zone_t;
typedef struct {
unsigned long mem[KMEMSIZE >> 15];
size_t offset;
} bitmap_allocator_t;
buddy_zone_t zone;
bitmap_allocator_t bitmap_allocator;
static inline int is_power_of_2(size_t x) { return !(x & (x - 1)); }
static inline int log2(size_t x) {
int y = !is_power_of_2(x);
while (x >>= 1) ++y;
return y;
}其中 buddy_free_area_t 用于维护一个空闲链表以及它的伙伴使用情况,而 buddy_zone_t 用于维护所有的空闲链表和空闲页数,bitmap_allocator_t 用于在初始化时简单地分配 bitmap 内存。
而 log2 用于求一个整数向上取到最接近的二的次幂的次数,MARK_USED 用于标记空闲链表中伙伴的使用情况,LONG_ALIGN 则负责把需要的位数转换成需要的长整型数量,在分配 bitmap 的时候会使用到。
unsigned long *alloc_bitmap(size_t bitmap_size) {
unsigned long *ptr = bitmap_allocator.mem + bitmap_allocator.offset;
assert(ptr < bitmap_allocator.mem + sizeof(bitmap_allocator.mem));
bitmap_allocator.offset += bitmap_size;
return ptr;
}
static void buddy_init(void) {
for (int i = 0; i < MAX_ORDER; ++i) {
list_init(&zone.free_area[i].free_list);
}
bitmap_allocator.offset = 0;
zone.nr_free = 0;
size_t size = KMEMSIZE >> 12;
for (int i = 0;; i++) {
unsigned long bitmap_size;
list_init(&(zone.free_area[i].free_list));
if (i == MAX_ORDER - 1) {
zone.free_area[i].map = NULL;
break;
}
bitmap_size = (size - 1) >> (i + 4);
bitmap_size = LONG_ALIGN(bitmap_size + 1);
zone.free_area[i].map = (unsigned long *)alloc_bitmap(bitmap_size);
}
}初始化时,首先将所有空闲链表初始化。然后为 bitmap 分配足够的空间,大小就是当前阶管理的内存页数的一半位,再除以 32 则得到需要的 32 位长整型的数量。
这里有一个自相矛盾的过程,由于此时还没有内存分配器,所以没有办法动态地为 bitmap 分配内存。有两种解决的办法:
- 使用前面实现的 First-Fit 分配器先行分配,等伙伴系统完成初始化之后,将 First-Fit 分配器占用的内存释放掉。
- 直接预先使用静态变量分配足够的空间,需要的时候直接从这个空间取。
为了简单起见,这里采用了第二种方法,最大需要的位数也只是 KMEMSIZE >> 12,也就是页数个比特位。再除以 32 就是需要的长整型的数量。
static void buddy_init_memmap(struct Page *base, size_t n) {
assert(n > 0);
struct Page *p = base;
for (; p != base + n; p++) {
assert(PageReserved(p));
p->flags = p->property = 0;
set_page_ref(p, 0);
list_init(&(p->page_link));
buddy_free_pages(p, 1);
}
}对于扫描到的每一块内存,要将其加入到伙伴系统,就只要一页一页地进行释放即可。在释放页面的函数中会自动合并。
static struct Page *buddy_alloc_pages(size_t n) {
size_t order = log2(n);
unsigned long min;
min = 1UL << order;
if (zone.nr_free < min) return NULL;
buddy_free_area_t *area;
unsigned int current_order;
struct Page *page;
unsigned int index;
// 从块的小到大遍历伙伴系统
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = zone.free_area + current_order;
if (list_empty(&area->free_list)) // 当前阶没有空闲块
continue;
page = le2page(list_next(&area->free_list), page_link); // 找到了空闲块
list_del(&(page->page_link)); // 删掉,可能会被分裂
index = page - pages; // 第几页?
if (current_order != MAX_ORDER - 1)
MARK_USED(index, current_order, area);
zone.nr_free -= 1UL << order;
return expand(page, index, order, current_order, area); // 分裂页面
}
return NULL;
}对于分配过程而言,首先检查当前的可用内存是否足够,然后从需要分配的页面数对应的阶的链表开始往高阶链表查询,找到一个足够大的空闲块后,就将其从对应的空闲链表中删除。由于分配到的空闲块可能比需要的更大,所以还要对空闲块进行进一步的划分。
static inline struct Page *expand(struct Page *page, unsigned long index,
int low, int high, buddy_free_area_t *area) {
unsigned long size = 1 << high; // 当前空闲块的大小
while (high > low) {
area--; // 往低阶链表走
high--;
size >>= 1; // 大小减半
list_add(&(area->free_list), &(page->page_link));
MARK_USED(index, high, area); // 伙伴被使用了
index += size;
page += size;
}
return page;
}在 expand 函数里,size 表示当前空闲块的大小,index 表示页号,page 指向当前空闲块的首页,high 表示当前空闲块所在的阶,low 表示分配需要的阶。分裂的过程如下:
- 如果当前空闲块所在的阶比需要的阶更高,说明需要继续分裂。
- 将空闲链表指针指向低一阶的空闲链表,然后对应的
high和size减小。 - 将当前的首页加入到低阶空闲链表中。
- 由于后面的一页是要被使用的,所以标记伙伴位表示这个分裂后的空闲块被使用了。
- 页号和首页地址指向分裂后的空闲块的后一半的起始地址。
- 回到第一步。
static void buddy_free_pages(struct Page *page, size_t n) {
unsigned int order = log2(n);
unsigned long mask;
buddy_free_area_t *area;
mask = (~0UL) << order;
area = zone.free_area + order;
if (!PageReserved(page)) {
size_t page_idx = page - pages;
assert(!(page_idx & ~mask));
assert(page_idx <= (KMEMSIZE >> 12));
size_t index = page_idx >> (1 + order);
zone.nr_free -= mask;
while (mask + (1 << (MAX_ORDER - 1))) {
struct Page *buddy;
assert(area < zone.free_area + MAX_ORDER);
if (!test_and_change_bit(index, area->map)) break;
buddy = pages + (page_idx ^ -mask); // 找到伙伴
list_del(&(buddy->page_link));
mask <<= 1;
area++;
index >>= 1;
page_idx &= mask;
assert(page_idx <= (KMEMSIZE >> 12));
}
list_add_before(&area->free_list, &(pages + page_idx)->page_link);
}
}释放的过程则是分配的反过程。首先需要确认释放的页面和释放的大小是否对应,然后开始释放。然后从当前阶开始递归地合并页面。合并页面主要有以下步骤:
-
检查当前阶是不是最高阶,是的话表示合并结束。
-
检查自己的伙伴是不是空闲的,如果不是,就不能继续合并了。
-
如果自己的伙伴是空闲的,那么就找到当前页的伙伴。对于伙伴系统,有一个非常重要的性质,那就是伙伴之间的页号只相差一个比特位。假如说当前阶数是
order,说明一个空闲块大小为2^order次方,这个相差的比特位就是从低位数起的第order + 1位。也就是说,如果一个页面的页号是0x70,对应二进制是0011 0000,又知道它的阶数是order == 4,那么它的伙伴就是0010 0000,也就是0x20。需要注意的是0x30的 4 阶伙伴不是0x40,因为它们不一样的比特位不止一个。利用这个性质,可以快速地找到伙伴的页号。假如知道当前阶数是
order,那么只要将自己的页号从低位数起的第order + 1位反转,就找到了伙伴的页号。而mask是一个低order位为 0,其余位为 1 的掩模,假如order为 4 的话,那么mask就是1111 0000(省略更高位的 1),而反转第order + 1位只需要将当前页号和只有第order + 1位的为 1 的二进制数进行异或操作,这个例子里也就是0001 0000。很容易就知道这个数正是mask的补码。也就是说,要找到伙伴的页号,只需要将自己的页号和
mask的补码进行异或即可。 -
找到伙伴之后,将它从它的空闲链表中删除,因为要和自己合并。
-
往高阶链表前进,假如两个伙伴在
order阶,那么合并之后的页号就是任意一个伙伴页号的低order + 1阶清零得到的数。 -
回到第一步。
循环终止的时候,说明已经不能再合并了,此时 page_idx 存放着合并完成的空闲块的首页页号,而 area 也指向了当前空闲块对应阶数的空闲链表,此时只要将对应的首页加入到空闲链表,就完成了释放。
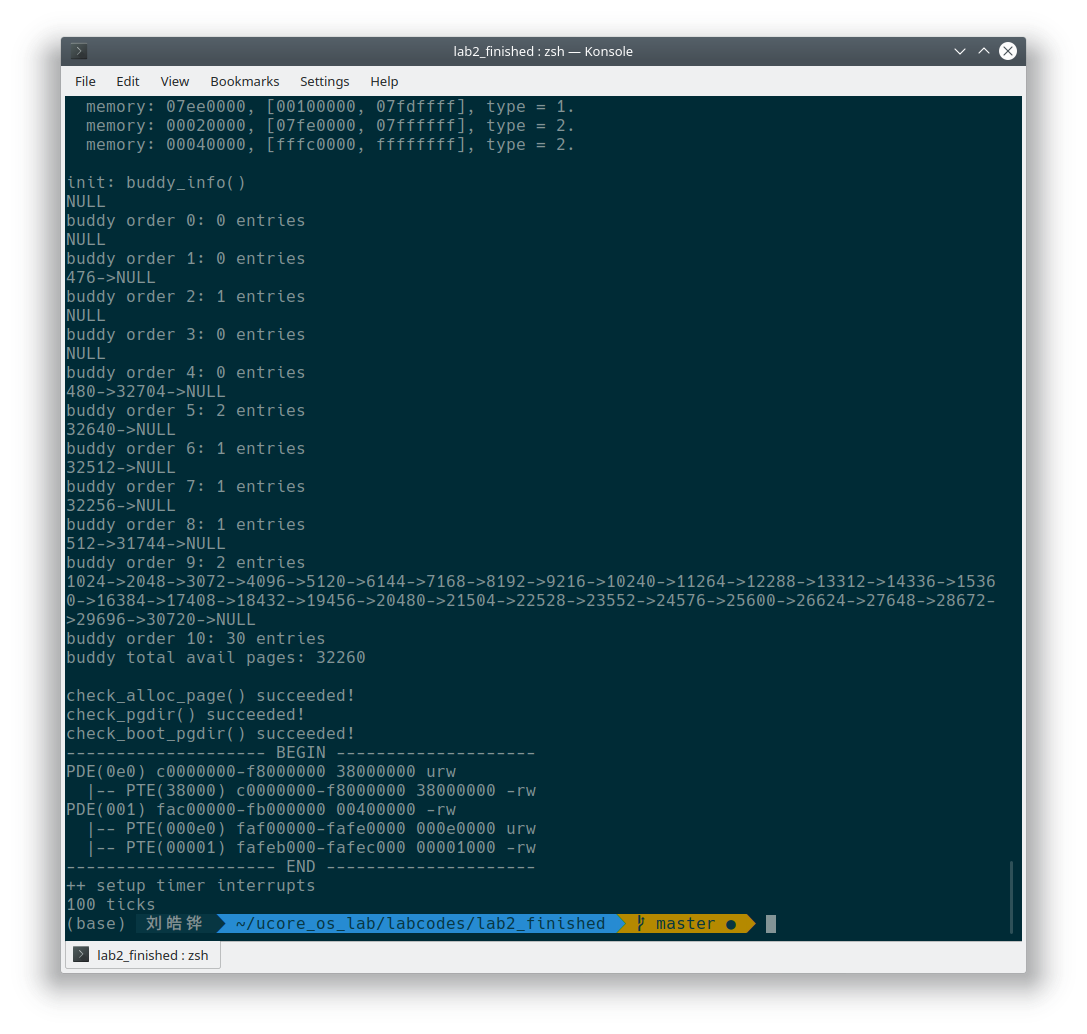
执行 make qemu 可以看到伙伴系统中自由链表的情况。