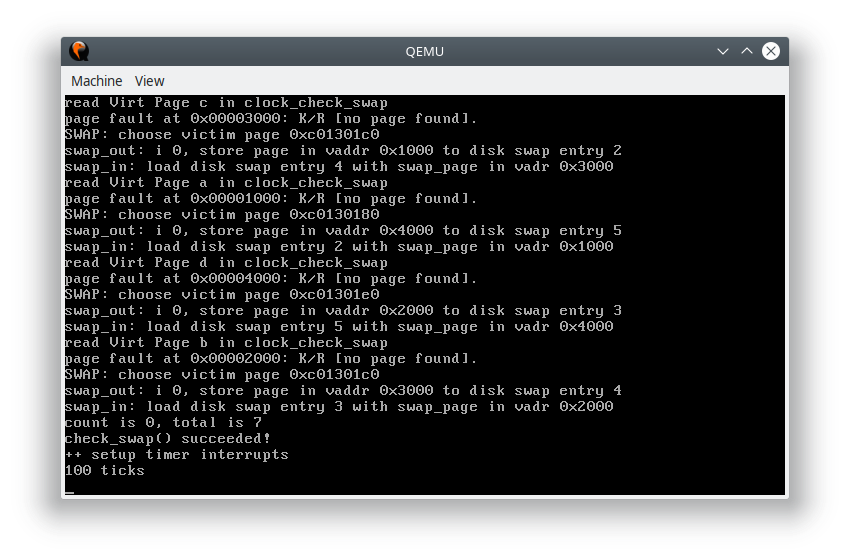
练习 1 给未被映射的地址映射上物理页
int
do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr) {
// ...
pte_t *ptep=NULL;
if (!(ptep = get_pte(mm->pgdir, addr, 1))) goto failed; //(1) try to find a pte, if pte's PT(Page Table) isn't existed, then create a PT.
if (*ptep == 0) {
if (!pgdir_alloc_page(mm->pgdir, addr, perm)) goto failed; //(2) if the phy addr isn't exist, then alloc a page & map the phy addr with logical addr
} else {
// Exercise 2
}
ret = 0;
failed:
return ret;
}启动分页机制以后,当程序尝试访问一个不在物理内存中的页帧或是访问权限有错的时候,会触发 CPU 的页面异常(Page Fault),进入中断处理程序。do_pgfault 的作用就是负责处理页面错误。
练习 1 处理的是地址还没有映射上物理页的情况。在这种情况下,只需要调用 Lab 2 中负责物理内存管理的函数即可。pgdir_alloc_page 就是用来给这个空地址映射上物理页的。
-
请描述页目录项(Page Directory Entry)和页表项(Page Table Entry)中每个组成部分的含义以及对 ucore 而言的潜在用处。
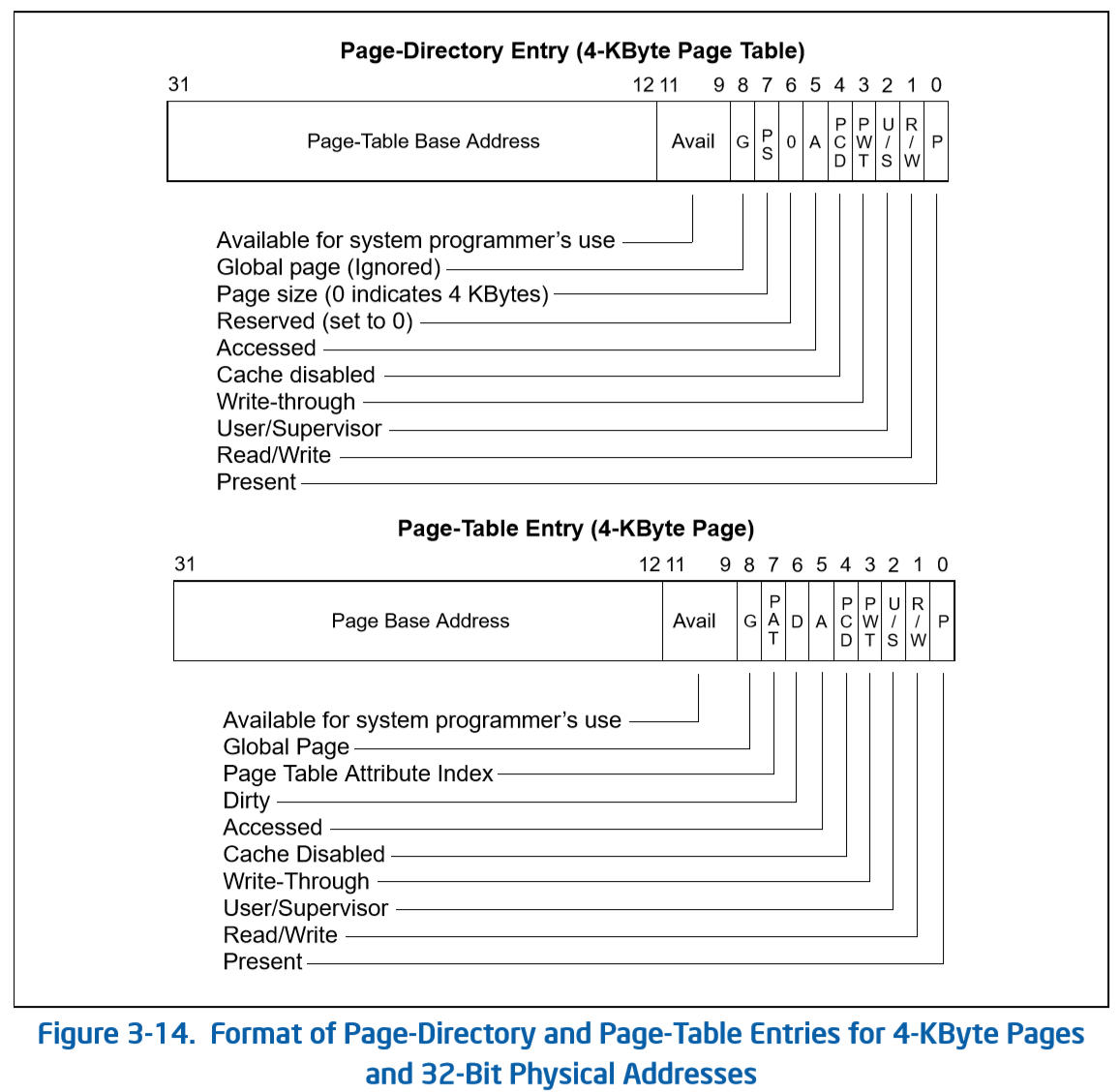
参考 Intel 官方手册,可以知道在页大小为 4KB 每页的时候,PDE 和 PTE 的高 20 位是物理基址,9-11 位为空闲位,操作系统可以自由使用。低八位为标志位,此时 PDE 与 PTE 的标志位含义有所不同,但它们的低三位都是一样的,分别用于权限控制,读写控制,以及标志该项是否有效。
-
如果 ucore 缺页服务例程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
-
将错误码压入栈中,表明此次页访问异常的具体错误,错误码具体格式如下:

-
将访问异常的线性地址放到
CR2寄存器中。 -
触发 14 号中断,将控制权移交中断服务例程。
-
练习 2 补充完成基于 FIFO 的页面替换算法
if(swap_init_ok) {
struct Page *page=NULL;
swap_in(mm, addr, &page); //(1)According to the mm AND addr, try to load the content of right disk page
// into the memory which page managed.
page_insert(mm->pgdir, page, addr, perm); //(2) According to the mm, addr AND page, setup the map of phy addr <---> logical addr
swap_map_swappable(mm, addr, page, 1); //(3) make the page swappable.
page->pra_vaddr = addr;
} else {
cprintf("no swap_init_ok but ptep is %x, failed\n",*ptep);
goto failed;
}首先把被换出的页面换入内存中,然后将该页重新插入页表项里,标识该页为可换出页,最后设置该页用于页置换算法的虚拟地址为当前访问的地址。
static int
_fifo_map_swappable(struct mm_struct *mm, uintptr_t addr, struct Page *page, int swap_in)
{
list_entry_t *head=(list_entry_t*) mm->sm_priv;
list_entry_t *entry=&(page->pra_page_link);
assert(entry != NULL && head != NULL);
//record the page access situlation
/*LAB3 EXERCISE 2: YOUR CODE*/
//(1)link the most recent arrival page at the back of the pra_list_head qeueue.
list_add_before(head, entry);
return 0;
}在 FIFO 页面替换算法中,每当有新的一页可以用于交换,说明该页刚刚被换入,则将其插入到访问队列的队尾中。
static int
_fifo_swap_out_victim(struct mm_struct *mm, struct Page ** ptr_page, int in_tick)
{
list_entry_t *head=(list_entry_t*) mm->sm_priv;
assert(head != NULL);
assert(in_tick==0);
/* Select the victim */
/*LAB3 EXERCISE 2: YOUR CODE*/
//(1) unlink the earliest arrival page in front of pra_list_head qeueue
list_entry_t *first = head->next;
//(2) assign the value of *ptr_page to the addr of this page
struct Page* page = le2page(first, pra_page_link);
*ptr_page = page;
list_del(first);
return 0;
}在需要换出页面的时候,按照 FIFO 算法,队首的页面是最早被换入的,所以直接将队首的元素删除,代表队首的页面被换出。
-
如果要在 ucore 上实现 “Extended Clock 页替换算法”,现有的
swap_manager框架是否足以支持在 ucore 中实现此算法?如果是,请给你的设计方案。如果不是,请给出你的新的扩展和基于此扩展的设计方案。并需要回答如下问题:- 需要被换出的页的特征是什么?
对于每个页面都有两个标志位,分别为使用位 A 和修改位 D。换出页的使用位必须为 0,表示该页在之前一段时间未被使用。并且算法优先考虑换出修改位为零的页面,以免频繁地将内存中的物理页写入磁盘而增大开销。
- 在 ucore 中如何判断具有这样特征的页?
当内存页被访问后,MMU 将在对应的页表项的
PTE_A这一位设为1,当内存页被修改后,MMU 将在对应的页表项的PTE_D这一位设为1。- 何时进行换入和换出操作?
当进程访问的物理页没有在内存中缓存而是保存在磁盘中时,需要进行换入操作; 当位于物理页中的内存被页面替换算法选择换出时,需要进行换出操作。
运行结果: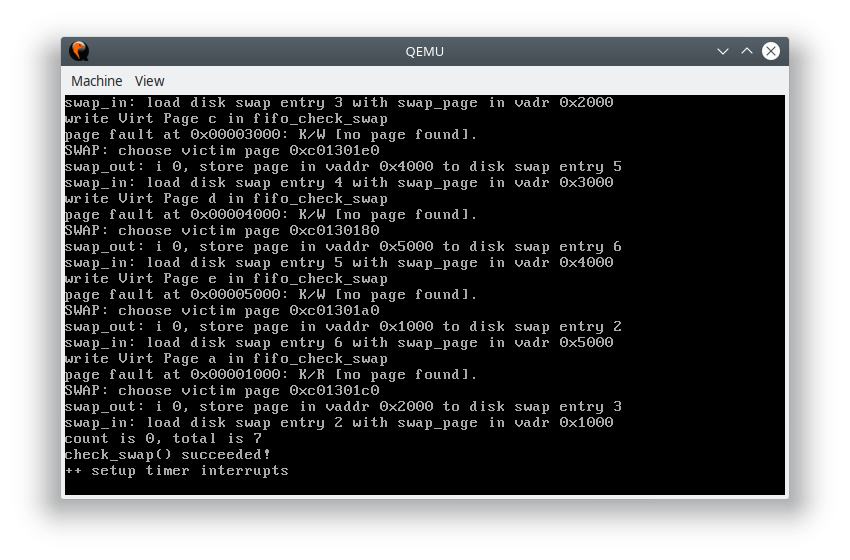
扩展练习 Challenge 1 实现识别 Dirty Bit 的 Extended Clock 页替换算法
static int _clock_init_mm(struct mm_struct *mm) {
mm->sm_priv = NULL;
return 0;
}
static int _clock_map_swappable(struct mm_struct *mm, uintptr_t addr,
struct Page *page, int tick) {
list_entry_t *head = (list_entry_t *)mm->sm_priv;
list_entry_t *entry = &(page->pra_page_link);
assert(entry != NULL);
if (head == NULL) {
list_init(entry);
mm->sm_priv = entry;
} else {
list_add_before(head, entry);
}
return 0;
}
static int _clock_swap_out_victim(struct mm_struct *mm, struct Page **ptr_page,
int in_tick) {
list_entry_t *head = (list_entry_t *)mm->sm_priv;
list_entry_t *p = head, *victim = NULL;
do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and not dirty
if (!(*ptep & PTE_A) && !(*ptep & PTE_D)) {
victim = p;
break;
}
p = list_next(p);
} while (p != head);
if (!victim) do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and dirty
if (!(*ptep & PTE_A) && (*ptep & PTE_D)) {
victim = p;
break;
}
*ptep &= ~PTE_A;
tlb_invalidate(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr);
p = list_next(p);
} while (p != head);
if (!victim) do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and not dirty
if (!(*ptep & PTE_A) && !(*ptep & PTE_D)) {
victim = p;
break;
}
p = list_next(p);
} while (p != head);
if (!victim) do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and dirty
if (!(*ptep & PTE_A) && (*ptep & PTE_D)) {
victim = p;
break;
}
*ptep &= ~PTE_A;
tlb_invalidate(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr);
p = list_next(p);
} while (p != head);
if (list_empty(victim)) {
mm->sm_priv = NULL;
} else {
mm->sm_priv = list_next(victim);
list_del(victim);
}
*ptr_page = le2page(victim, pra_page_link);
return 0;
}在普通的 Clock PRA 算法里,只考虑了页面是否被访问,但是没有考虑页面是否脏页,显然脏页换出的代价比非脏页更大,因此在 Extended Clock PRA 里,还要优先选择不是脏页的页面。
在 Extended Clock PRA 中,插入和 FIFO PRA 一样,直接插入到链表尾部。在选择需要被换出的页面的时候,从上一次被换出页的下一页开始扫描,需要至多四趟扫描:
- 寻找没被访问 (
PTE_A == 0) 而且没被修改的非脏页 (PTE_D == 0),其中PTE_A和PTE_D都是 CPU 硬件置位的。 - 寻找没被访问 (
PTE_A == 0) 的脏页 (PTE_D == 1),并且将途中扫描到的页面的PTE_A都修改为 0 - 重复 1
- 重复 2
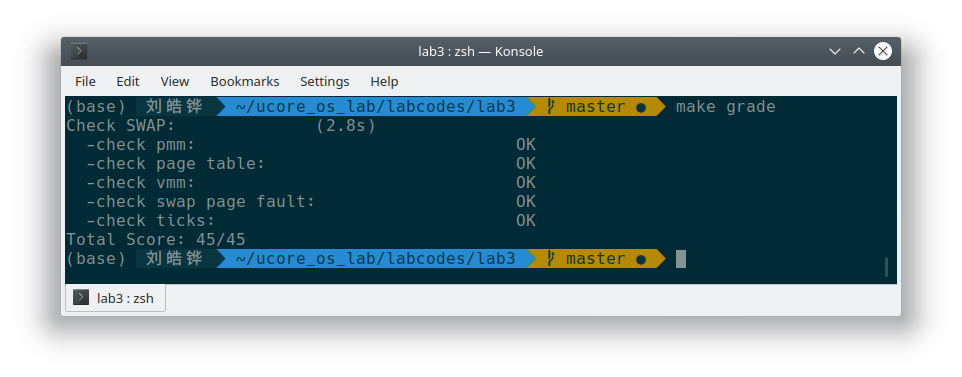
运行结果: